Audit
Introduction
Flowable creates a technical audit trail (history) by default. When it is required to have a business audit trail, the audit task is the easiest way to do this.
The audit stream is created using audit instances (audit entries) being added for whatever reason. Those audit entries are later queried using filtering aspects like the scope, type, or user depending on the needs and angles to look into auditing.
The Audit Instance
Scoping and Permissions
An audit instance should always be scoped to a context it belongs to. Although the builder API does not explicitly enforce it to be set, it is a good practice to always include a scope to an audit entry. It might even be something like scope type global and any scope ID you like, but scoping is usually the key for permissions and filtering, so a very important concept.
There are a couple of predefined scope types you can create audit entries for like bpmn or cmmn for the scope of a process or case, respectively. More scope types include task, conversation, user or user-account.
It does not stop there, you can add your own scope types as well as client or claim or whatever you need to build a stream for later on. Another example might be to save audit entries whenever some important settings are changed like setting some thresholds or escalation settings, changing an SLA and the like. You might want to use scope type settings there, and the scope ID would point to the exact setting which was changed.
The scope type and scope ID are always used together. The scope type defines the type of object or context the audit instance is bound to, and the scope ID references the exact object. As an example, you might use scope type bpmn and the scope ID contains the process instance id to bind an audit entry to a particular process instance.
The scope is typically used for permission handling as well when retrieving audit entries. The permission to see the audit entry is derived from its scope by default. If you created an audit instance scoped to a process instance, you need to have access to the process itself to also gain access to the audit entries scoped with it.
When you use the default audit REST endpoint to filter audit entries, there are only a few permission handlers yet available to make sure you only get the entries you are allowed to see, furthermore, the scope always needs to be present for a query, so it is meant to be used for scoped audit streams only using the built-in handlers like for processes, cases and tasks as an example.
When you build your own custom scopes or want to create an audit stream within another context than a single scope, you need to create your own REST endpoint for that by using the Java query API internally.
 note
noteIf you create your own REST endpoint to query for audit entries, always think about the permissions of the audit entries! Who is able to see what entry? What permissions do I need to check when querying for audit instances? Otherwise, you might leak classified information to be seen by users not entitled to see such information.
The sub scope ID is optional and further specifies the context of the audit instance. As an example you might use bpmn as the scope type and the process instance id as the scope ID and use a task id as the sub scope ID to bind the audit entry to the process as its main scope, but also point out that it was created in the context of a particular task within the process.
You can optionally also set the scope definition ID to the scoped object model for instance. This way you might later filter for all entries created within a specific type of process model.
Type and Sub Type
Beyond the scope you can define the type and sub type for an audit entry. Most likely it is used for later filtering so be careful and think about the requirements for the audit stream you need to query and render to set appropriate type information.
Using an example for approvals, building just an approval audit stream in a dashboard where you want to see everything around approvals, no matter the process or user, just approvals. Then you could set the type to approval and use approved or declined as subtypes for instance.
noteAlthough the type and subType are custom fields for an audit entry, there are some predefined ones used in the audit view on a case or process like create or complete where if known, another icon is rendered for the entry according the type.
Message and category properties
2026.1.0+The audit Message and Category are now standalone properties of the audit task, configured directly in its property panel. Previously they could only be provided as the message and category keys inside the payload.
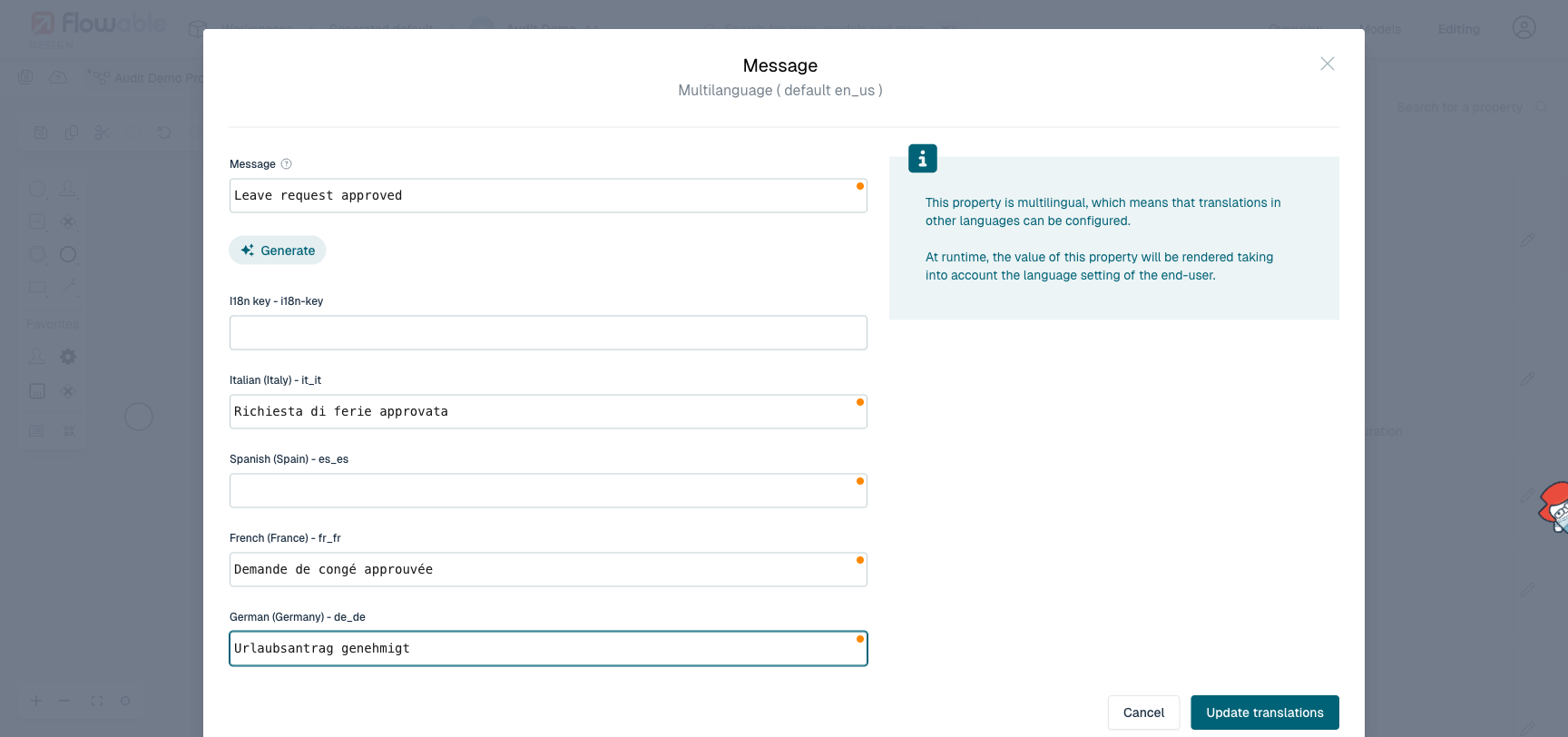
The Message can also be defined in multiple languages. Open the multilanguage editor on the Message field to provide the message per language. At runtime the default audit trail renders the message in the viewing user's language.
Payload
The payload is optional and might contain additional information for the audit entry. You can add an arbitrary number of additional data to the payload, there is no limitation, just keep the overall data you produce through those audit entries in mind.
There are some predefined keys for the payload in order to be rendered in the default audit trail UI of a case or process (see above that this has changed starting from 2026.1.0):
message: the string added to the payload using this key is rendered as the content of the audit entry. It might as well be set in Design as an expression, as an example,${findUser(authenticatedUserId).displayName} has approved the request '${root.name}' with comment: ${comment}.would evaluate that string before it is set as the message in the payload of an audit entry.category: usesystemoruserto set the category for the audit entry to be rendered accordingly in the default audit UI.
Audit Task Property Details
| Property | Description |
|---|---|
| Creator id | If left empty, the currently authenticated user is taken by default. But you can also enter an expression resolving to a user id, if you want the entry being created in the context of someone else. That might make sense if you run stuff asynchronously and want to make sure the correct user is entered here. |
| External id | This one is completely custom, so you can use it with whatever you want. It might point to an external important data object being changed, or any contextual reference or information you might want to use or filter the entries with. |
| Type | The type of the entry is custom, so you can use the type and sub type as you want. When defining type / sub type ask yourself what you want to filter for later on. |
| Sub type | The sub type gives more details about the type. As an example, you might want to use approval as the type, then the sub type further specifies the entry like approved or declined or timed out or delegated. |
| Scope ID | The scope ID contains the id of the context for the audit entry. For a process, use the process instance id. |
| Sub scope ID | The sub scope is optional and might further specify the scope / context for the entry, such as a task id. |
| Scope type | The type needs to define the object we reference using the scope ID, so scope ID and scope type identify the context for the audit entry and usually defines the permissions too. |
| Scope definition ID | The optional definition id or model key of the scoped object which can be used for filtering later on. |
| Payload | The payload is optional and might contain additional information. The message and category are predefined keywords used in the standard audit UI. |
| Payload / category | Default values for the category are user and system but you can use any custom one. |
| Payload / message | The message used in the default audit UI, might even contain an expression to be resolved when creating the audit entry. |
Java API
The Flowable audit capabilities are exposed to developers through the AuditService, which provides the following capabilities:
- Generate Audit Entries
- Query Audit Entries
- Update Audit Entries
- Delete Audit Entries
Properties
General
| Attribute | Type | Description | Category |
|---|---|---|---|
| Model Id | Text | Model Id identifies the element within the process model. | The model id, name and documentation properties can be found on any element. They are used respectively to uniquely identify the audit task, to give it a user-friendly name and to add a free-form description. |
| Name | Text | The name of the element. This is the name displayed in the diagram. | |
| Documentation | Multiline Text | A free-form text that can be used to explain details about the particular element. | |
| Store result variable transiently | Boolean | Flag that marks that the result of the expression will not be persisted at the end of the database transaction. Use this if you do not want to store a result after the next wait state, e.g. if you only need access to the result inside a condition. | |
| Payload | List | The content of the audit log. | The payload is optional and might contain additional information that is stored together with the audit instance. An arbitrary number of additional data can be added to the payload. |
| Creator Id | Text | Creator id points to the creator who created audit log instance. If empty, default audit service creator is used. | Audit instances generated by the audit task are meant to be queries through the REST or Java API. Configuring the following identifiers will make filtering easier. Creator id: If left empty, the currently authenticated user is taken by default. An expression resolving to a user id can be set here, if the instance should be created in the context of someone else. That might make sense for example if executing asynchronously and wanting to make sure the correct user is entered. External id: this one is completely custom. |
| External Id | Text | External id points to the external system entity. | |
| Type | Text | The audit log type. | Audit instances generated by the audit task are meant to be queries through the REST or Java API. To allow for filtering, various types can be set. Type and Subtype are both custom properties. The subtype should give more details about the type, but it's fully customizable. |
| Sub type | Text | The audit log sub type. | |
| Scope Id | Text | Scope id points to the scope under which the audit task log is created. If all of scope attributes are empty, current scope is used. | Scoping is an important aspect of an audit instance. A scope points to the context it belongs to. This can be a process or case instance or anything else. Audit instances generated by the audit task are meant to be queried later on. Adding proper scope information makes querying easier. The Scope id, Subscope id, Scope type can be used to associate it with the current instance and task information. The Scope definition ID can be used to point to the corresponding process or case definition, or something completely custom. |
| Sub scope Id | Text | Sub scope id points to the sub scope under which the audit task log is created. If all of scope attributes are empty, current sub scope is used. | |
| Scope type | Text with suggestions:
| Scope type defines the type of the scope and sub scope instances. If all of scope attributes are empty, current scope type is used. | |
| Scope definition id | Text | Scope definition id points to the definition from which audit log was created. If all of scope attributes are empty, current scope definition id is used. |
Multi Instance
Multi instance
| Attribute | Type | Description | Category |
|---|---|---|---|
| Multi instance type | Selection:
| The type of multi-instance: default is 'None' meaning a single instance is created at runtime. Select either 'Parallel' or 'Sequential' if you want multiple instances to be created. | Multi-instance is used to define the repetition of this audit task at runtime. Doing so allows to create multiple audit instances, either sequentially after each other or in parallel. For example, when referencing a collection an audit instance could be created for each element of that collection. |
| Collection | Text | References a collection variable (for example a JSON array variable) by its name or using an expression that resolves to a collection. | |
| Element variable | Text | The name of the variable where the currently processed element from the multi-instance collection configured above will be stored (for example, 'invoicePosition'). The element can then be accessed through an expression, e.g., ${invoicePosition}. | |
| Element index variable | Text | The name of the variable where the index of the currently processed item from the multi-instance collection will be stored, for example, 'itemIndex'. The index is a number starting with 0 which is increased with every element that is being created. The index can then be accessed through an expression, e.g., ${itemIndex} further on in the process. | |
| Cardinality | Text | A fixed number or an expression that resolved to an integer that controls the number of instances that will be created. This is typically used when there is no collection available or needed. | |
| Completion condition | Text | An expression that should resolve to a boolean value. When evaluating to true, the remaining activity instances will be removed and the process instance will continue. |
Variable aggregation
| Attribute | Type | Description | Category |
|---|---|---|---|
| Variable Aggregations | List | Define an aggregation. Each element in this list will result in one aggregation variable. | When having multiple instances of this audit task, there could be a need to create an aggregation of the variables merged and/or updated in each instance. With variable aggregation, a JSON variable can be merged that after all instances have been completed contains the summary of all the used variables. This is needed because typically variables are persisted locally, to avoid clashes on the process instance level. Alternatively, an 'overview' variable can be merged while the instances are still unfinished. Each aggregation consists of one or multiple definitions that map instance variables of one instance to the single aggregation variable. |
Advanced
| Attribute | Type | Description | Category |
|---|---|---|---|
| Optimize for only automatic steps | Boolean | (Advanced setting, only check it if you understand the implications) If checked, this instructs the Flowable engine that the multi-instance only contains automatic tasks and no wait states. In this situation, an asynchronous job is created when the multi-instance activity is entered that keeps checking if all instances are completed and completes the multi-instance. The benefit of this approach is that it is light on resources versus alternatives and doesn't lead to optimistic locking exceptions. |
Advanced
Execution
| Attribute | Type | Description | Category |
|---|---|---|---|
| Skip expression | Text | If the Skip expression evaluates to true, the flow is taken regardless of any condition. It is required to opt-in to this feature by setting a variable _FLOWABLE_SKIP_EXPRESSION_ENABLED with the Boolean value true on the process instance. | When the Skip expression resolves to true, this audit task will not be executed at runtime. The Include in history flag can be used to store the historical entry of this audit task when running with a history level that normally would not store the execution of the audit task. Note that this flag has no effect when running with history level 'none'. |
| Include in history | Boolean | When the history level is set to "instance" or "task" level with this property it can be configured if this activity instance should be included in the historic activity data. | |
| Is for compensation | Boolean | Determines whether the activity can serve as a compensation for another activity. | A BPMN transaction is a set of activities that logically belongs together. Transactions can be cancelled through the Cancel End Event and handled through the Cancel Intermediate Boundary Event. The Is for compensation field can be used to indicate that the audit task is meant as compensation steps for another activity. |
| Asynchronous | Boolean | When enabled, the activity will be started as an asynchronous job. The process state is persisted before this element is executed. Then, the process execution will be resumed asynchroneously. This can be used when the execution an activity takes a long time to return the UI to the user quicker in case the user does not need to see the next step immediately. However, if an error occurs before the following wait state, there will be no direct user feedback. Please refer to the documentation for more details. | When making the audit task asynchronous, the audit instance will be created in the background. This is useful for example to not block the UI of a user, however creating such entry typically doesn't take much time. Choose exclusive to avoid other asynchronous steps of this process instance to run at the same time. When Leave asynchronously is enabled, the activity will be left as an asynchronous job. This means that the activity is ended asynchronously. |
| Exclusive | Boolean | Determines whether the activity or process is run as an exclusive job. An exclusive job makes sure that no other asynchronous exclusive activities within the same process are performed at the same time. This helps to prevent failing jobs in concurrent scenarios. | |
| Leave asynchronously | Boolean | When enabled, the activity will be left as an asynchronous job. This means that the activity is ended asynchronously, including end execution listeners. Please refer to the documentation for more details. | |
| Leave exclusive | Boolean | Determines whether the activity should leave as an exclusive job. An exclusive job makes sure that no other asynchronous exclusive activities within the same process are performed at the same time. This helps to prevent failing jobs in concurrent scenarios. | |
| Job Category | Text | When set, the underlying generated job will have a Job Category, which will be executed only by Application Servers, where the Process Engine has enabledJobCategories set to this category. |
Advanced options
| Attribute | Type | Description | Category |
|---|---|---|---|
| Exception Mappings | List | Define one or more exception mappings to map a technical Java exception to a BPMN error code. | Map technical java exceptions to BPMN error codes that can be caught with a boundary error event. |
| Failed job retry time cycle | ComplexTrigger | Service task logic defined with a failed job retry time cycle |
Listeners
| Attribute | Type | Description | Category |
|---|---|---|---|
| Execution listeners | List | Allows invoking custom after certain lifecycle events. Start: Executes after the activity has been started. End: Executes after the activity was completed. Transition: When defined on a sequence flow, executes once the flow is transition is taken. | Execution listeners are used to add logic on certain lifecycle events. Typically it is used to add extra technical logic which shouldn't be visible in the BPMN process model. |
Visual
| Attribute | Type | Description | Category |
|---|---|---|---|
| Background color | Color | The background color of the element in the diagram. | Visual properties that determine how the audit task is shown in the diagram. This has no impact on the runtime execution. |
| Font size | Selection:
| Font size. | |
| Font weight | Selection:
| Select the style between bold and normal. | |
| Font style | Selection:
| Select the style between italic and normal. | |
| Font color | Color | Select a font color. | |
| Border color | Color | The border color of the element in the diagram. |
List Attribute Details
Payload
| Attribute | Type | Description |
|---|---|---|
| Name | Text | The name of the element. This is the name displayed in the diagram. |
| Value | Text |
Variable Aggregations
| Attribute | Type | Description |
|---|---|---|
| Target (Variable / Expression) | Text | The name of the target variable or an expression that gives the variable name |
| Type | Selection:
| The type of aggregation. Use 'default' to use the standard behavior of creating an aggregation JSON variable. Use 'custom' to define a delegate expression that will handle the aggregation. Please see the documentation for more information. |
| Delegate Expression | Text | Define a delegateExpression that will resolve to an instance of VariableAggregator (for BPMN) or PlanItemVariableAggregator (for CMMN). This instance will then be responsible for aggregating the variables. |
| Class | String | A class that implements VariableAggregator (for BPMN) or PlanItemVariableAggregator (for CMMN). This instance will then be responsible for aggregating the variables. |
| Target variable creation | Selection:
| Configures the way the aggregation variable is created. The 'Default' option creates the aggregation variable when all instances of the multi-instance have been completed. Use 'Create overview variable' to create a variable at the start of the multi-instance and keep it up to date during multi-instance exeution. Once all the instances are completed it will create a JSON variable in the same way as for Default target variable creation. Use the 'Store as transient variable' option to have the default behavior, but store the resulting aggregation variable transiently. |
| Variable Definitions | BasicFormList | property.loopVariableAggregation.definitions.description |
Variable Definitions
| Attribute | Type | Description |
|---|---|---|
| Source (Variable / Expression) | Text | The name of the source variable or an expression that provides the value |
| Target (Variable / Expression) | Text | The name of the aggregation variable or an expression that resolves to a variable name. |
Exception Mappings
| Attribute | Type | Description |
|---|---|---|
| Error code | Text | The code of an error definition. |
| Exception class name | Text | |
| Root cause | Text | |
| Include child exceptions | Boolean |
Failed job retry time cycle
| Attribute | Type | Description |
|---|---|---|
| Time cycle | Text |
Execution listeners
| Attribute | Type | Description |
|---|---|---|
| Event | Selection:
| The lifecycle event. The 'Take' event is only available for sequence flow. |
| Class | Text | Fully qualified classname of a class to be invoked when executing the task. The class must implement either JavaDelegate or ActivityBehavior. |
| Expression | Text | JUEL Expression to be executed when the task is started. Expressions allow you to interact with the backend by calling services, making calculations etc. You can find more information about expressions in the documentation. |
| Delegate expression | Text | Delegate Expression to be executed when the task is started. A delegate expression must resolve to a Java object, for instance a Spring bean. The object's class must implement either JavaDelegate or ActivityBehavior. |
| Fields | List |
Fields
| Attribute | Type | Description |
|---|---|---|
| Name | Text | The name of the element. This is the name displayed in the diagram. |
| String value | Text | |
| Expression | Text | JUEL Expression to be executed when the task is started. Expressions allow you to interact with the backend by calling services, making calculations etc. You can find more information about expressions in the documentation. |
| String | Text |